6.2 K近邻分类器
分类:智能算法在高光谱遥感数据处理中的应用864字
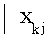
K近邻是基于实例的学习方法中最基本的一种算法,它不同于eager学习算法,K近邻方法在训练阶段只是简单地把训练样例存储起来,把建模过程推迟到要预测新实例的工作阶段,因此K近邻是一种典型的lazy学习算法。在分类中,K近邻方法适用于目标函数值是离散的情况,而在回归中,它则适用于目标函数值是连续的情况。K近邻方法的学习过程主要分为两个步骤:第一步是找到预测新实例的K个邻居;第二步根据这K个邻居来预测新实例的目标值。
如图6-2-1中所示,未知样本到已知类别A中心的距离比它到已知类别B中心和C中心的距离都小,因此未知类X属于类别A。
图6-2-1 KNN分类原理
K近邻算法假定所有的实 ...... (共864字) [阅读本文]>>
 上一篇
上一篇
.jpg)
.jpg)